

Sequence Mining and Pattern Analysis in Drilling Reports
A more detailed report of this work can be found in arXiv.org: Hoffimann et al., 2017. Sequence Mining and Pattern Analysis with Deep Natural Language Processing.
Drilling activities in the oil and gas industry have been reported over decades for thousands of wells on a daily basis, yet the analysis of this text in large-scale for information retrieval, sequence mining, and pattern analysis is very challenging.
Drilling reports contain interpretations written by drillers from noting measurements in downhole sensors and surface equipment, and can be used for operation optimization and accident mitigation.
In this work, in collaboration with Youli Mao during a summer internship at Halliburton Inc., we developed an intelligent system on top of TensorFlow™ and Keras for automatic classification of sentences written in drilling reports for hundreds of wells in an actual field.
Methodology
After important meetings with the client, we were provided drilling reports for more than 300 wells. In this simple investigation, we were interested in classifying every sentence written in the reports into three labels:
- EVENT — A major accident or failure in the drilling operation (e.g. the drilling tool may become stuck in the pipe).
- SYMPTOM — An observable symptom before the failure (e.g. erratic torque, fluid leakage).
- ACTION — An action taken in order to remediate or to prevent the failure.
Based on these labels (and the sequences in which they appear), a dedicated intelligent system can be trained to act in real-time, preventing future accidents.
In order to teach the machine the meaning of sentences, we start by teaching it the meaning of its constituent words. In deep learning termonology, these are called word vectors, as illustrated in the figure below.
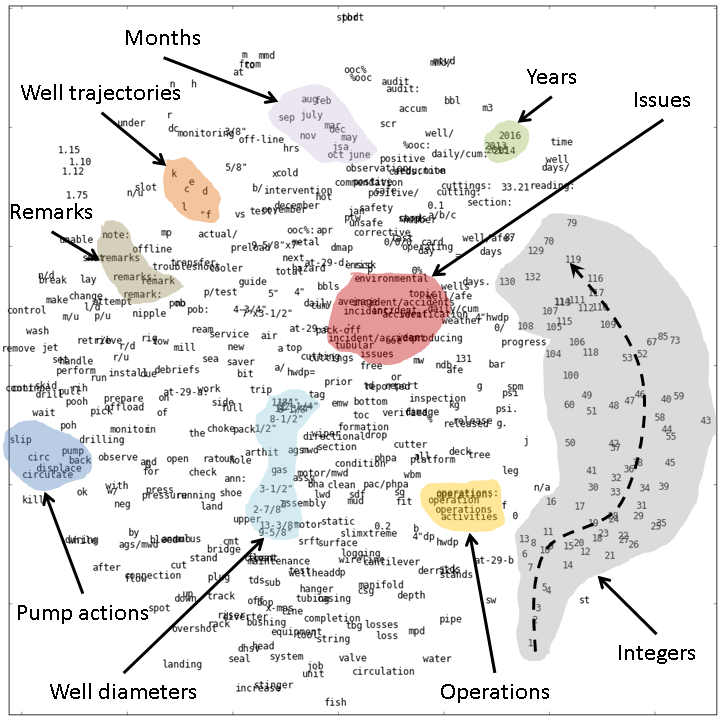
These words learned without supervision are then passed as features to another layer of a deep neural network for supervised sentence classification. We trained simple, convolutional, and recurrent neural networks on the labeled data, and applied the best of the three (LSTM ~ 83% accuracy) to all the wells in the field.
Results
Below we illustrate a few sentence classifications with the LSTM and the corresponding confusion matrix:

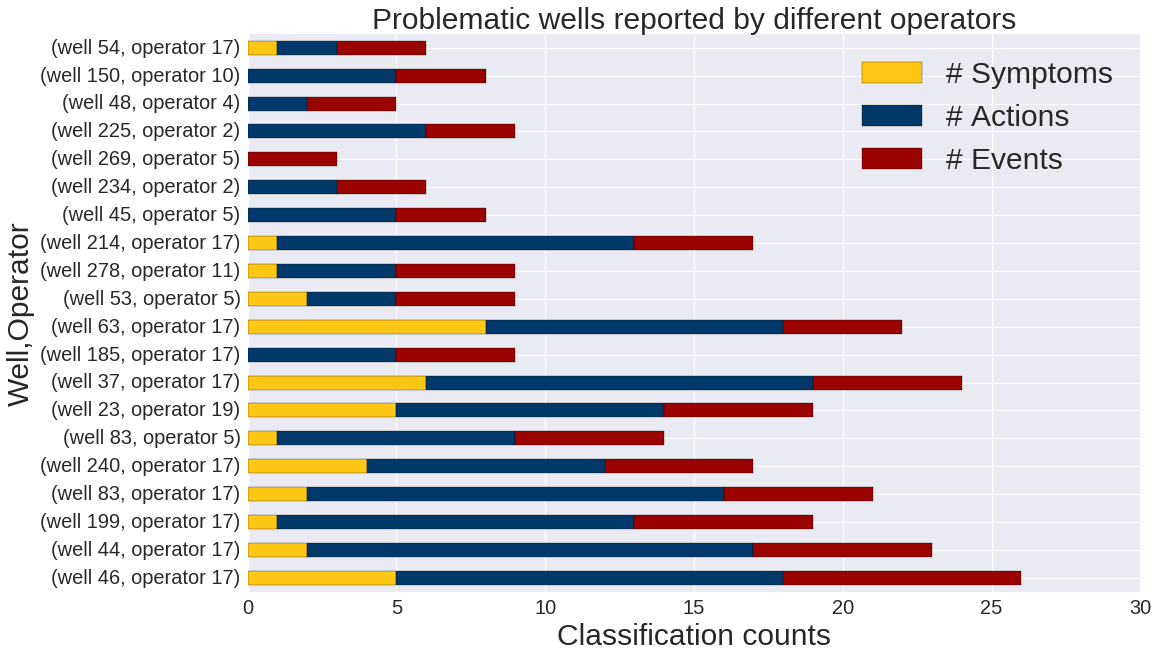
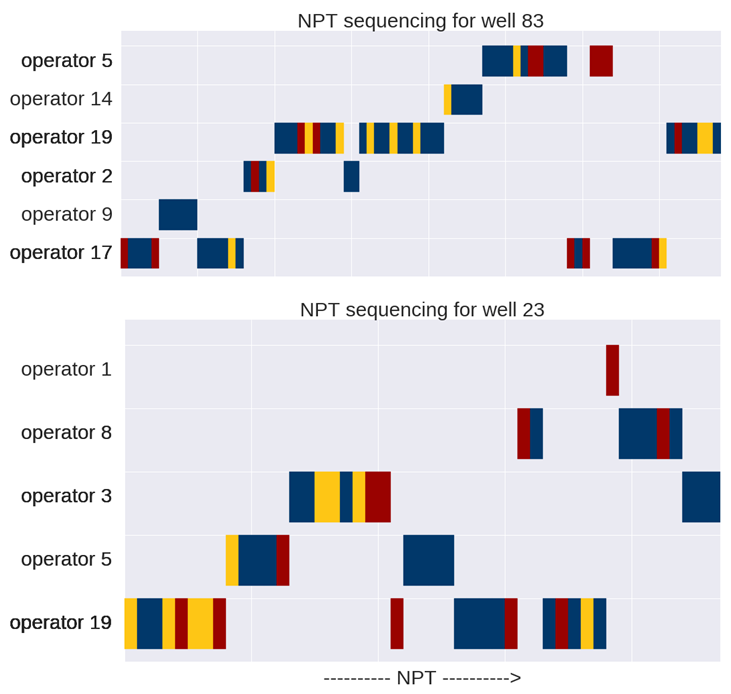
Given the classification results, the client was able to perform advanced queries on the dataset for further investigation. For example, the most problematic wells—wells containing the highest number of events as classified by the LSTM—are plotted below. More interestingly, sequences of labels were easily queried, and patterns started to emerge about how companies behave differently, according to their roles and interests.
The results obtained in this project are just an initial step towards a smarter decision support system. Future work includes acquisition of more data and design of larger neural network architectures for automatic report generation.